IFG: Internet-Scale Functional Grasping
Carnegie Mellon University
* indicates equal contribution

Abstract
Large Vision Models trained on internet-scale data excel at segmenting and semantically understanding object parts, even in cluttered scenes. However, while these models can guide a robot toward the general region of an object, they lack the geometric precision needed to control dexterous robotic hands for precise 3D grasping. To address this, IFG leverages simulation through a force-closure grasp generation pipeline that captures local hand–object geometries, then distills this slow, ground-truth-dependent process into a diffusion model that operates in real time on camera point clouds. By combining the global semantic understanding of internet-scale vision with the geometric accuracy of simulation-based local reasoning, IFG achieves high-performance semantic grasping without any manually collected training data.
Grasps
Single Object Grasp Examples
Crowded Scene Grasp Examples
Method
Overview
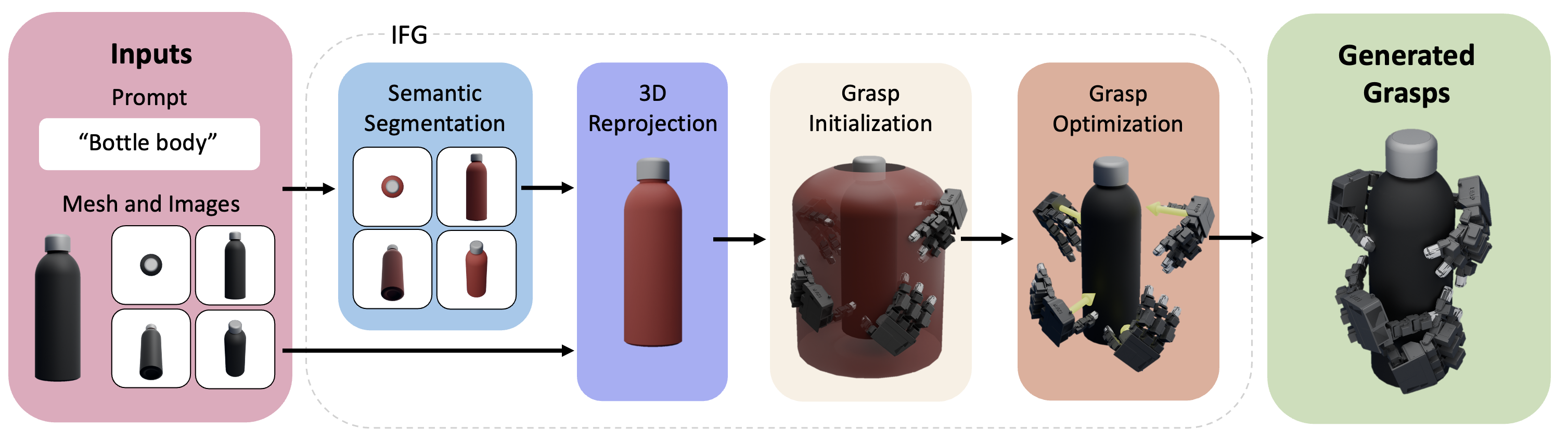
Pipeline
1) Inputs & Useful Region Proposal
IFG renders multi-view images and applies VLM-guided segmentation (SAM + VLPart) to extract task-relevant parts. These are reprojected to 3D and aggregated per mesh face to identify a “useful region” that localizes functional geometry.
2) Geometric Grasp Synthesis
Candidate hand poses are sampled near the useful region. A force-closure-based energy with joint limits and collision penalties is minimized to produce physically valid and functional grasps.
3) Simulation Evaluation
Each grasp is perturbed and tested in Isaac Gym on tasks such as Lift and Pick&Shake. Success rates across perturbations become continuous labels, and unstable grasps are filtered out.
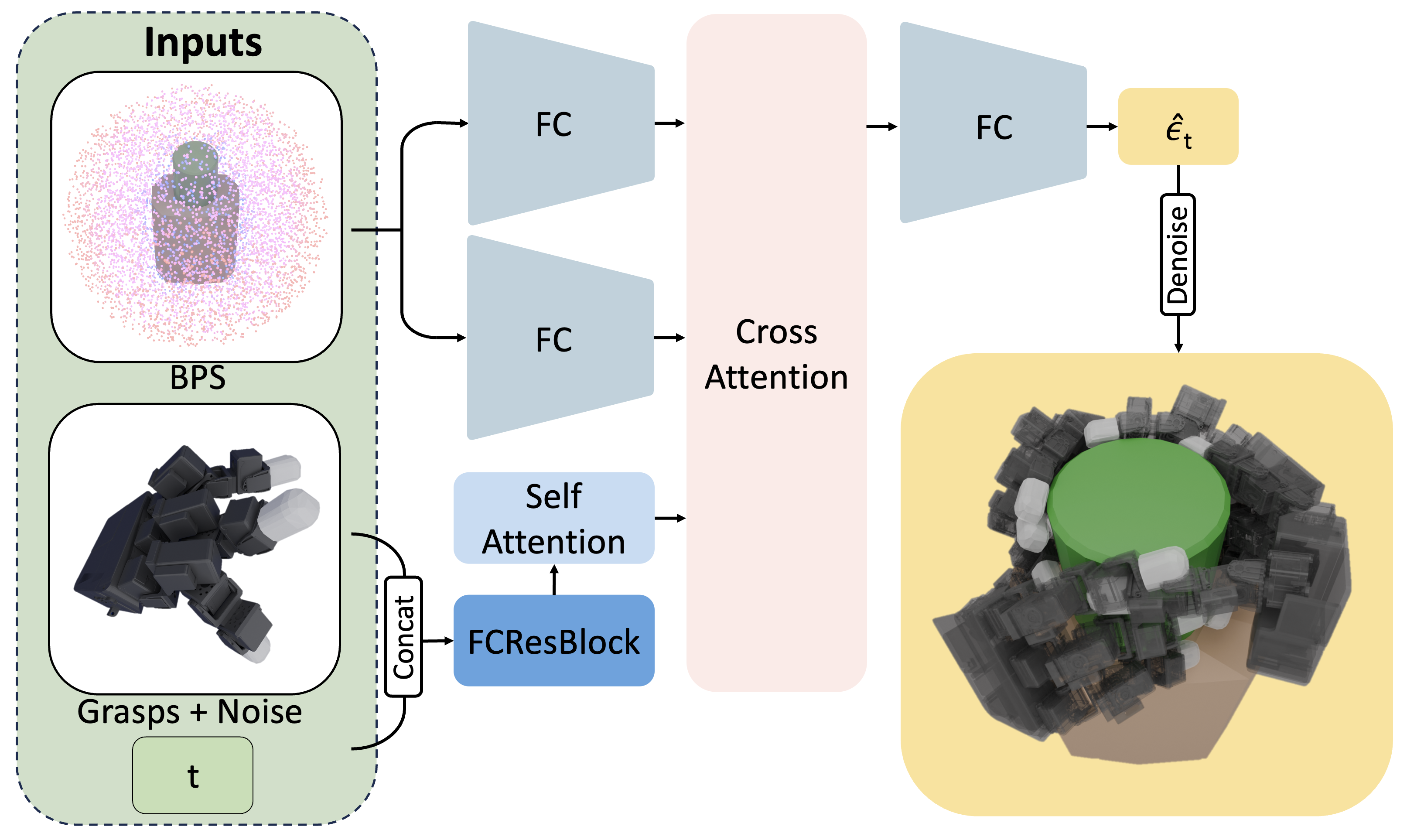
4) Diffusion Policy Distillation
A diffusion model is trained to map a noisy grasp and depth-based BPS input to a final grasp. This combines semantic priors from VLMs and geometric accuracy from optimization for fast inference.
Results
1. Qualitative Results
Our method produces stable and task-oriented functional grasps across diverse objects and environments. In single-object scenes, grasps align with affordance-relevant regions such as handles or rims. In crowded scenes, the VLM-guided segmentation allows IFG to isolate the correct target object and avoid collisions with distractors.

2. Generalization Across Objects
IFG generalizes to unseen object instances and novel categories without retraining. By combining visual-language part reasoning with geometric grasp optimization, our method successfully transfers to objects that differ in shape, topology, or affordance layout from training data. We evaluate this in both isolated scenes and cluttered arrangements.
| Object | Get a Grip | Ours |
|---|---|---|
| water bottle | 49.1 | 62.8 |
| large detergent bottle | 51.2 | 62.5 |
| spray bottle | 43.1 | 54.5 |
| pan | 48.1 | 52.1 |
| small lamp | 56.8 | 85.7 |
| spoon | 42.7 | 50.9 |
| vase | 32.2 | 55.9 |
| hammer | 45.8 | 45.8 |
| shark plushy | 19.8 | 25.1 |
| Object | DexGraspNet2 | GraspTTA | ISAGrasp | Ours |
|---|---|---|---|---|
| Tomato Soup Can | 47.8 | 38.3 | 52.0 | 45.5 |
| Mug | 33.2 | 26.9 | 22.6 | 60.4 |
| Drill | 32.1 | 20.8 | 36.4 | 57.5 |
| Scissors | 9.7 | 0.0 | 33.7 | 20.2 |
| Screw Driver | 0.0 | 8.3 | 40.0 | 22.0 |
| Shampoo Bottle | 50.6 | 25.4 | 18.8 | 53.1 |
| Elephant Figure | 23.6 | 29.6 | 24.2 | 35.8 |
| Peach Can | 61.8 | 28.0 | 55.3 | 60.3 |
| Face Cream Tube | 32.1 | 22.5 | 20.7 | 35.5 |
| Tape Roll | 22.7 | 13.9 | 9.8 | 43.2 |
| Camel Toy | 12.8 | 14.3 | 21.3 | 21.8 |
| Body Wash | 40.2 | 22.3 | 29.4 | 58.3 |
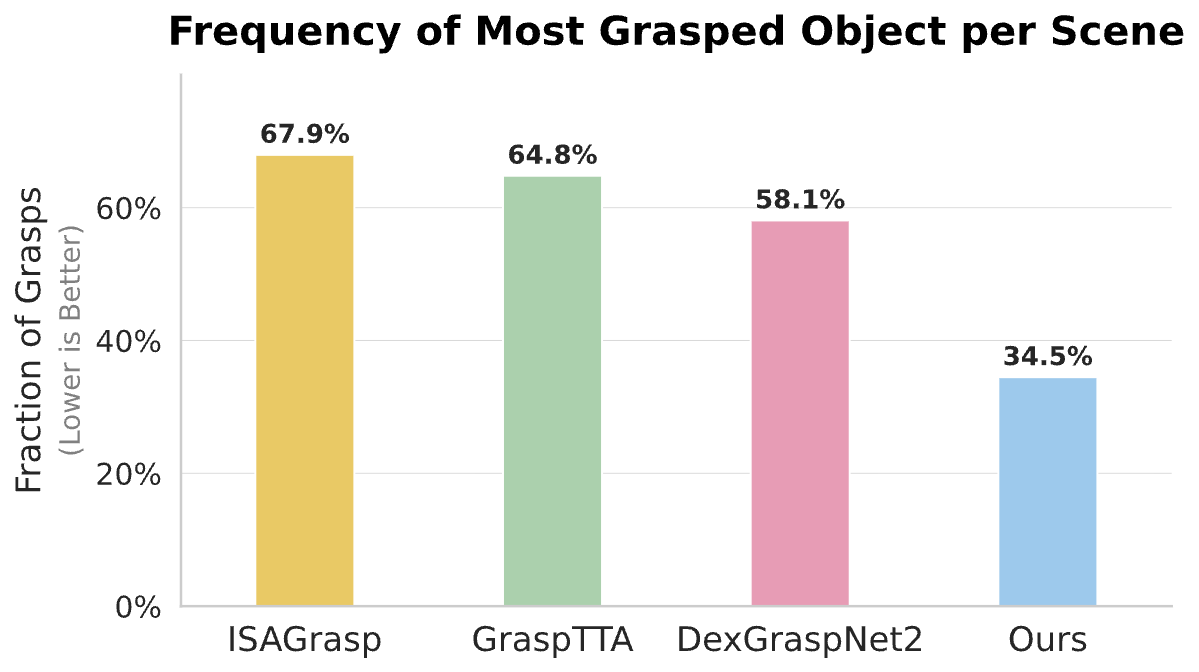
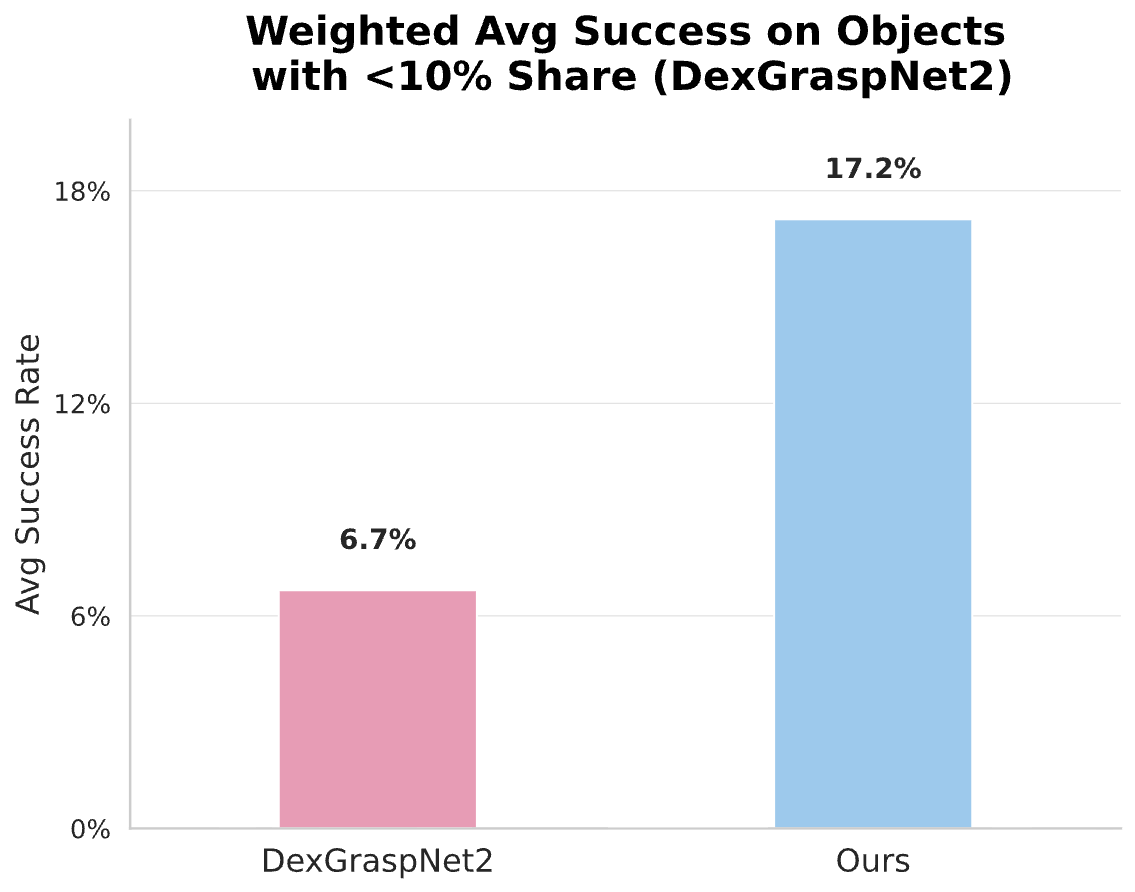
In single-object settings, IFG consistently outperforms Get a Grip across most categories, especially for functionally complex objects such as bottles, lamps, and vases. In crowded scenes, IFG achieves state-of-the-art performance, often surpassing DexGraspNet2, GraspTTA, and ISAGrasp by accurately focusing on the target object using language-guided segmentation.
Visualizations demonstrate IFG’s transfer to novel categories. In single-object settings, the method identifies object parts relevant to the task (e.g., mug handle, hammer shaft). In cluttered scenes, IFG isolates the correct object from nearby distractors and maintains collision-free grasp synthesis.
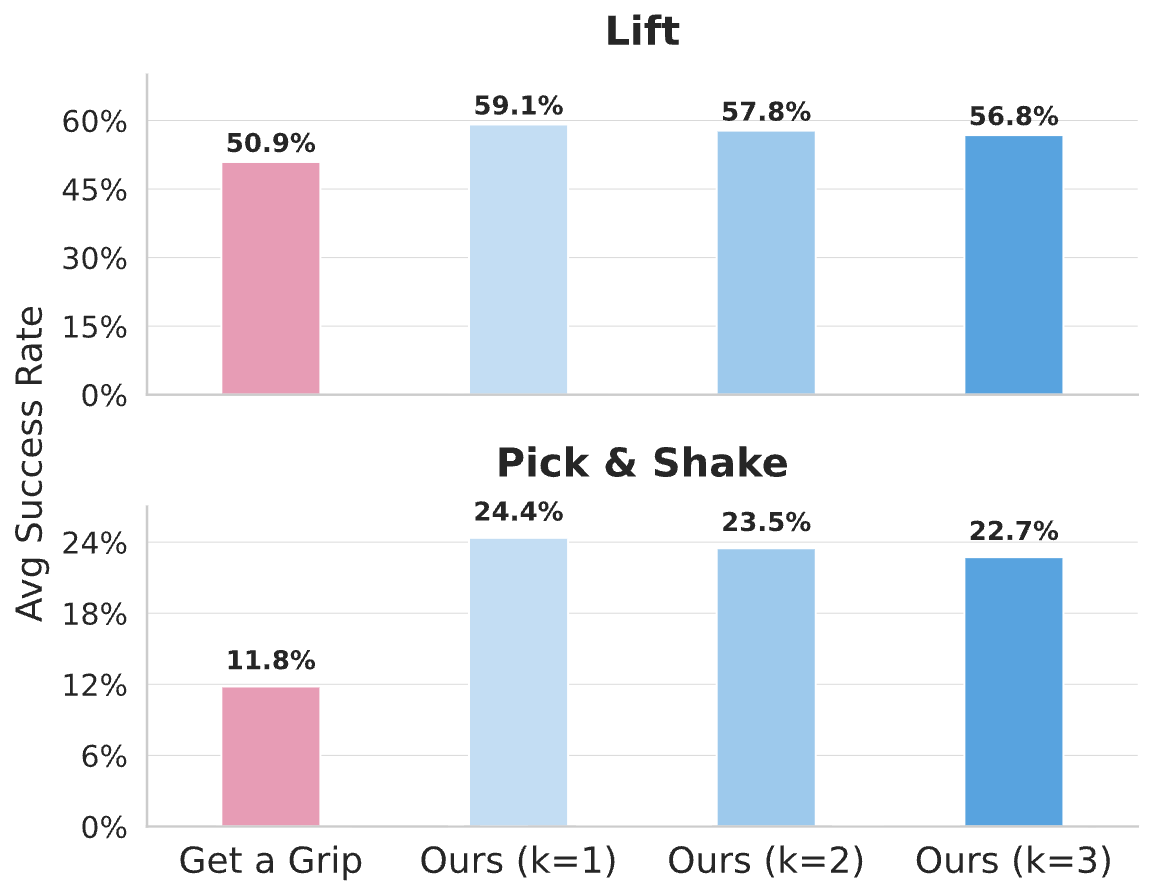
3. Generation Success Rate
We evaluate the quality of grasps generated before diffusion training by measuring physical execution success in simulation. IFG surpasses Get a Grip in single-object pick-and-place and pick-and-shake tasks. In crowded scenes, IFG remains competitive with large-scale pretrained models such as DexGraspNet2, despite using no supervised grasp annotations.
| Method | Pick & Shake (%) | Lift (%) |
|---|---|---|
| Ours | 16.14 | 51.11 |
| Get a Grip | 11.82 | 50.93 |
| Method | Lift (%) |
|---|---|
| Ours | 32.23 |
| GraspTTA | 25.64 |
| ISAGrasp | 32.51 |
| DexGraspNet2 | 36.71 |
4. Diffusion Success Rate
Finally, we distill optimized grasps into a diffusion model, enabling fast feedforward grasp generation. The diffusion model preserves task-oriented grasp behaviors and achieves high success rates during execution, validating that physically optimized grasps can be effectively transferred to a generative policy.
BibTeX
@misc{liu2025ifginternetscaleguidancefunctional,
title={IFG: Internet-Scale Guidance for Functional Grasping Generation},
author={Ray Muxin Liu and Mingxuan Li and Kenneth Shaw and Deepak Pathak},
year={2025},
eprint={2511.09558},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2511.09558},
}Acknowledgments
We thank Jason Liu, Andrew Wang, Yulong Li, Jiahui (Jim) Yang, Sri Anumakonda for helpful discussions and feedback. This work was supported in part by the Air Force Office of Scientific Research (AFOSR) under Grant No. FA955023-1- 0747 and by the Office of Naval Research (ONR) MURI under Grant No. N00014-24-1-2748.